Scraping structured data from web pages
This tutorial demonstrates how to use Fused User Defined Functions (UDFs) to scrape web pages and extract structured data. We'll walk through building a dataset of public schools from a specific geographic area using three different scraping approaches.
Introduction
Imagine you need to compile a comprehensive list of public schools for a specific area. A quick Google search leads us to the Top Ranked Public Schools website. This site contains multiple subpages for different locations like Connecticut or New York.
Each page displays only a limited number of schools initially, requiring users to click "see more" to load additional results. Our goal is to programmatically extract data from these pages and generate CSV files for any location without manual navigation.
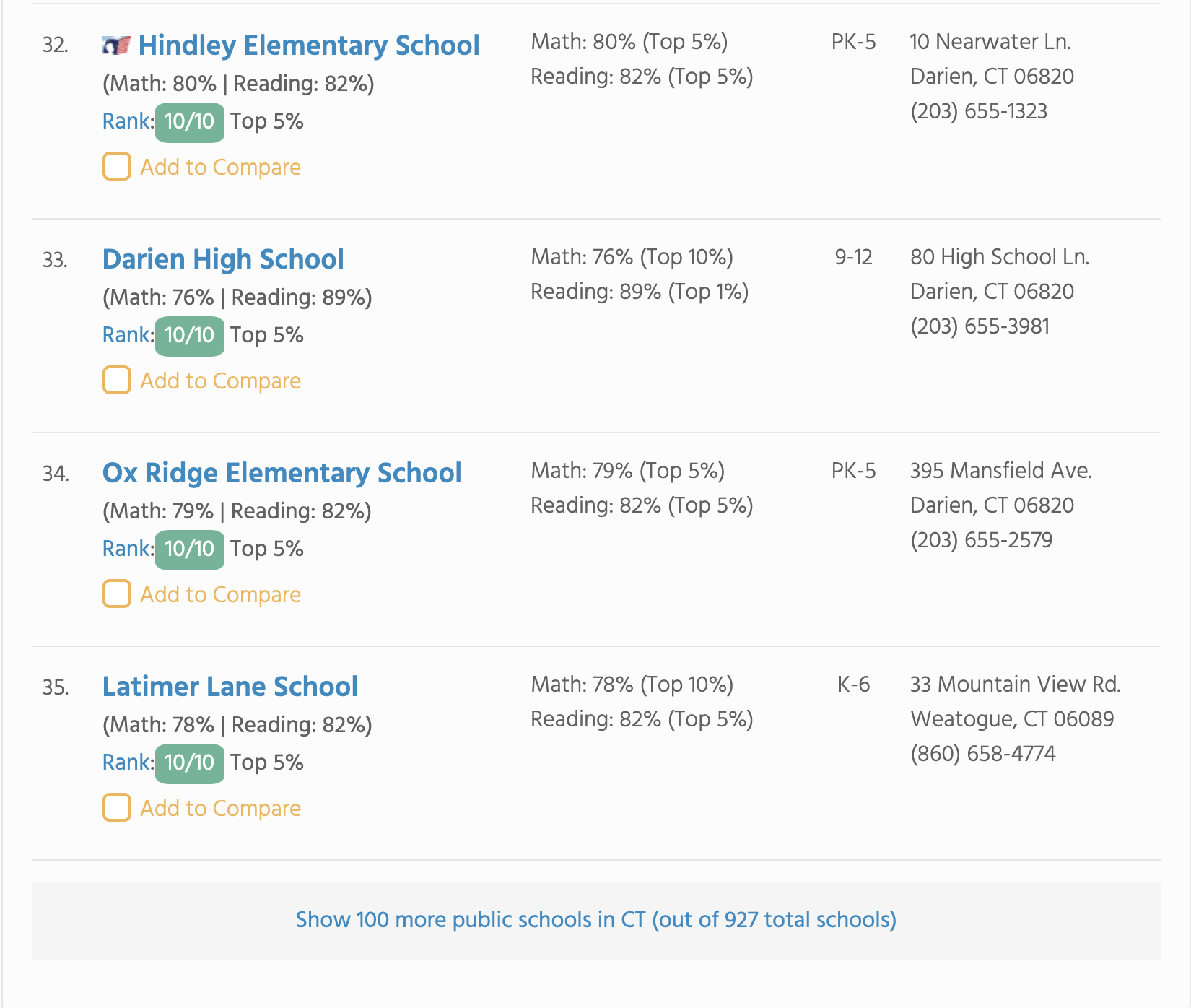
Method 1: Individual Page Scraping
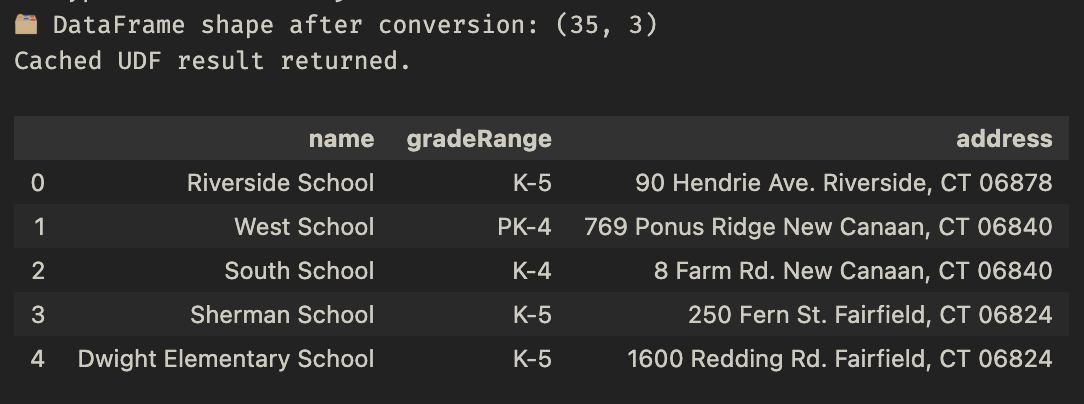
When you know the exact page URL and whether it contains paginated content, use the scrapegraph web scraper UDF to extract structured data from single pages.
Parameters
| Parameter | Type | Description |
|---|---|---|
| url | string | The target webpage URL to scrape |
| query | string | Natural language description of data to extract |
| output_schema | dict (optional) | Expected structure of the output data |
| pagination_pages | int (optional) | Number of paginated pages to scrape |
| scroll_pages | int (optional) | Number of scroll actions for infinite scroll pages |
Example Usage
Using the Python SDK:
import fused
df = fused.run(
"fsh_3A1QcdR5kJEwmDSkYxc934",
url="https://www.publicschoolreview.com/top-ranked-public-schools/connecticut/tab/all/num/1",
query="Extract school names, ranks, and addresses",
pagination_pages=2
)
df.head()
Output:
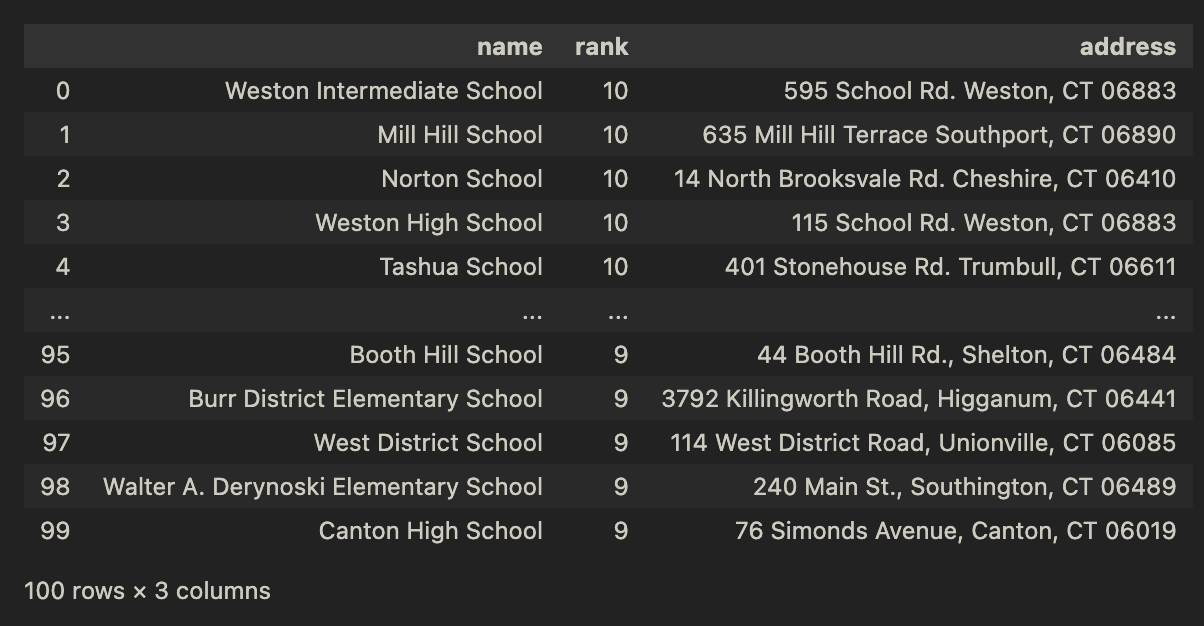
Method 2: Batch Scraping Multiple Pages
When you need to scrape data from multiple known URLs simultaneously, use the scrapegraph multi scraper UDF. This UDF creates a unified output schema across all pages and processes them in parallel using fused.submit calls.
Parameters
| Parameter | Type | Description |
|---|---|---|
| urls | list | List of webpage URLs to scrape in batch |
| query | string | Natural language description of data to extract |
| pagination_pages | int (optional) | Number of paginated pages to scrape per URL |
| scroll_pages | int (optional) | Number of scroll actions for infinite scroll pages |
Example Usage
Using the Python SDK:
import fused
df = fused.run(
"fsh_5WETmX04oWgWtSCxwv1ZNr",
urls=[
"https://www.publicschoolreview.com/top-ranked-public-schools/new-york/tab/all/num/1",
"https://www.publicschoolreview.com/top-ranked-public-schools/new-york/tab/all/num/3",
],
query="Extract school names, grade ranges, and addresses for all NYC schools"
)
df.head()
Output:
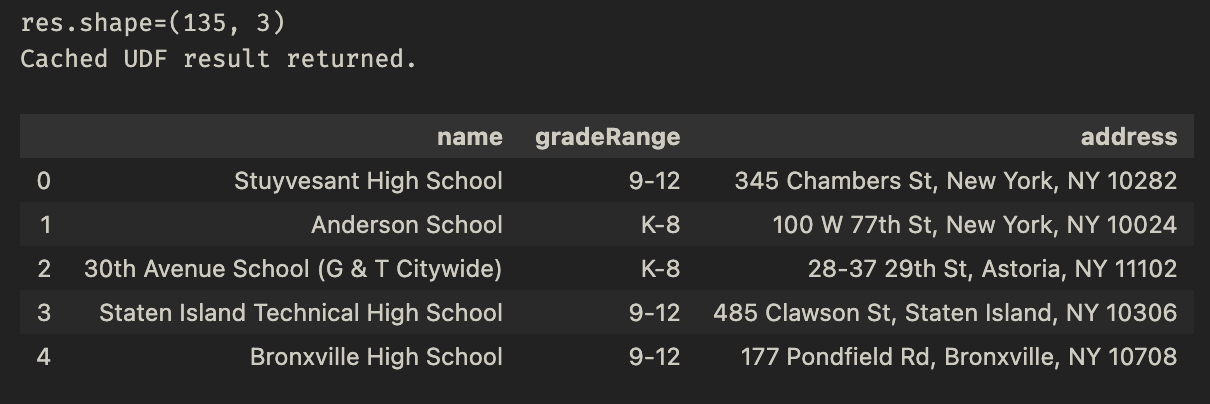
Method 3: Intelligent Crawling and Scraping
When you only know the top-level domain but not the specific page URLs, use the firecrawl search UDF to automatically discover and scrape relevant pages. This UDF crawls the website, identifies the most relevant pages based on your search criteria, and extracts the requested data.
Parameters
| Parameter | Type | Description |
|---|---|---|
| url | string | The base URL to crawl and search |
| search_prompt | string | Natural language description of content to find |
| extraction_prompt | string | Natural language description of data to extract |
Example Usage
Using the Python SDK:
import fused
df = fused.run(
"fsh_6mpu2dqoEBc1W80GjhZLSM",
url="https://www.publicschoolreview.com",
search_prompt="best public schools in connecticut",
extraction_prompt="Extract school names, grade ranges, and addresses"
)
df.head()
Output:
Using HTTPS API Endpoints
For integration into external systems or automated workflows, you can generate shared HTTPS endpoints for these UDFs. This allows you to retrieve data in CSV format using simple HTTPS requests.
Available Endpoints
Individual Page Scraper:
curl "https://www.fused.io/server/v1/realtime-shared/fsh_3A1QcdR5kJEwmDSkYxc934/run/file?format=csv"
Multi-Page Scraper:
curl "https://www.fused.io/server/v1/realtime-shared/fsh_5WETmX04oWgWtSCxwv1ZNr/run/file?format=csv"
Intelligent Crawler:
curl "https://www.fused.io/server/v1/realtime-shared/fsh_6mpu2dqoEBc1W80GjhZLSM/run/file?format=csv"
Making it Your Own
These are community UDFs that you can fork and customize for your needs. Simply click on the "Make a copy to modify" in the Fused Workbench to create your own copy.
API Setup Required: You'll need to configure your own API keys for third party services as fused secrets
See Also
- Turning any UDF into an API
- Letting anyone talk to your data through MCP Servers
- Running jobs in parallel with
fused.submit()
Note: These web scraping features are currently in active development and you may encounter occasional issues.